Text Extraction & Recognition ·
DhritiOCR: Document level OCR System for Malayalam
Document-level OCR pipeline for Malayalam-English documents with structure preservation, table reconstruction, and robust low-resource script recognition.

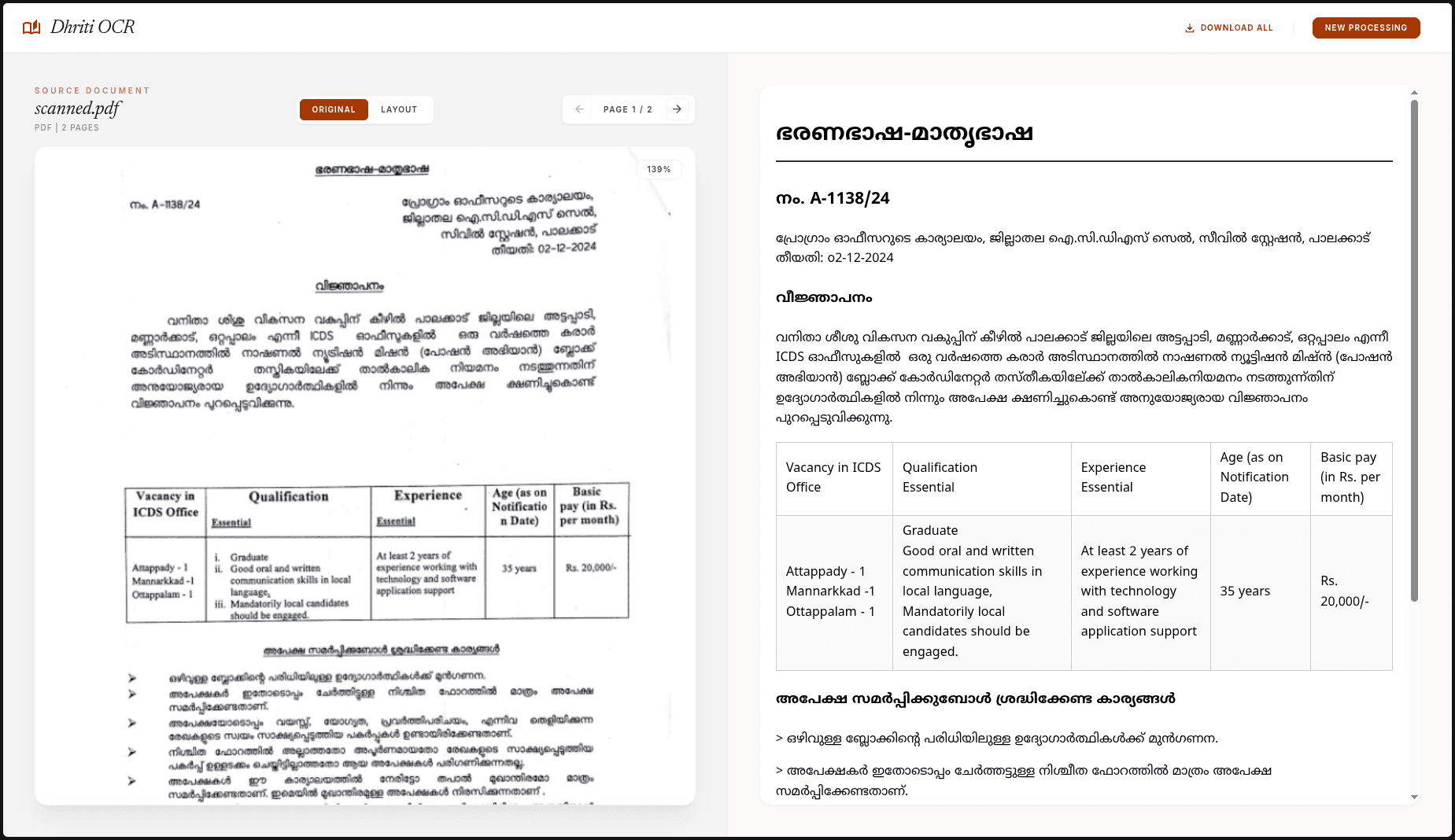
Landing experience with project context and entry points.
Problem Statement
Most OCR systems perform reliably on line-level Latin scripts but fail on dense, low-resource Indic documents where linguistic variation and complex layouts coexist. DhritiOCR was built to handle full-page extraction while preserving document semantics.
Architecture Breakdown
- Recognition Backbone: PaddlePaddle models fine-tuned for Malayalam + English
- Dataset Strategy: Custom synthetic engine (M-Synth) with dynamic string lengths
- Vision Layer: OpenCV preprocessing and region-level normalization
- Serving Layer: FastAPI orchestration for deterministic extraction workflow
Why This Needed Custom Engineering
Traditional training corpora underrepresent Malayalam orthography and omit real-world scan artifacts. For CTC-based recognition models, this causes alignment collapse, repeated-token confusion, and unstable decoding on variable-length sequences.
DhritiOCR addresses this through targeted synthetic data generation, script-aware augmentation, and explicit layout-stage routing before recognition.
Linguistic Roadblocks and Fixes
| Challenge | Technical Description |
|---|---|
| Old vs New Lipi Clash | Real documents mix traditional and reformed orthography; distinct mappings were required to avoid contextual collapse. |
| High Visual Similarity | Characters with near-identical geometry caused brittle predictions under blur/noise; targeted contrast and edge-case synthesis reduced confusion. |
| Chillu Handling | Pure consonants such as ൺ, ൻ, ർ required sequence-aware training and stricter region isolation to avoid neighboring merge artifacts. |
| Complex Ligatures | Koottaksharam formations produce non-linear glyph shapes and spacing, demanding robust CTC alignment exposure during training. |
Output Rendering Capabilities
DhritiOCR now supports readable text rendering and table-preserving extraction for scanned documents. This allows downstream systems to consume both narrative text blocks and structured tabular data without lossy conversions.
| Output Type | Support Level | Notes |
|---|---|---|
| Paragraph Text | Full | Script-aware extraction with line continuity |
| Headings/Subheadings | Full | Layout-aware hierarchy retention |
| Wired Tables | Full | Cell boundary tracing + row/column reconstruction |
| Mixed Malayalam-English Blocks | Full | Fine-tuned multilingual decoding path |
Engineering Outcome
The final system is production-oriented rather than demo-only: it is modular, debuggable, and designed for iterative model upgrades while preserving output compatibility.