Audio Processing & ML Pipelines ·
ADAPT: Audio Data Annotation and Preprocessing Tool
An industry-grade, scalable CLI pipeline for automated TTS and ASR dataset generation. ADAPT handles end-to-end ingestion, vocal separation, global speaker diarization, VAD-based slicing, and phonetic annotation while specifically solving cross-chunk speaker ID mismatches for large corpora.
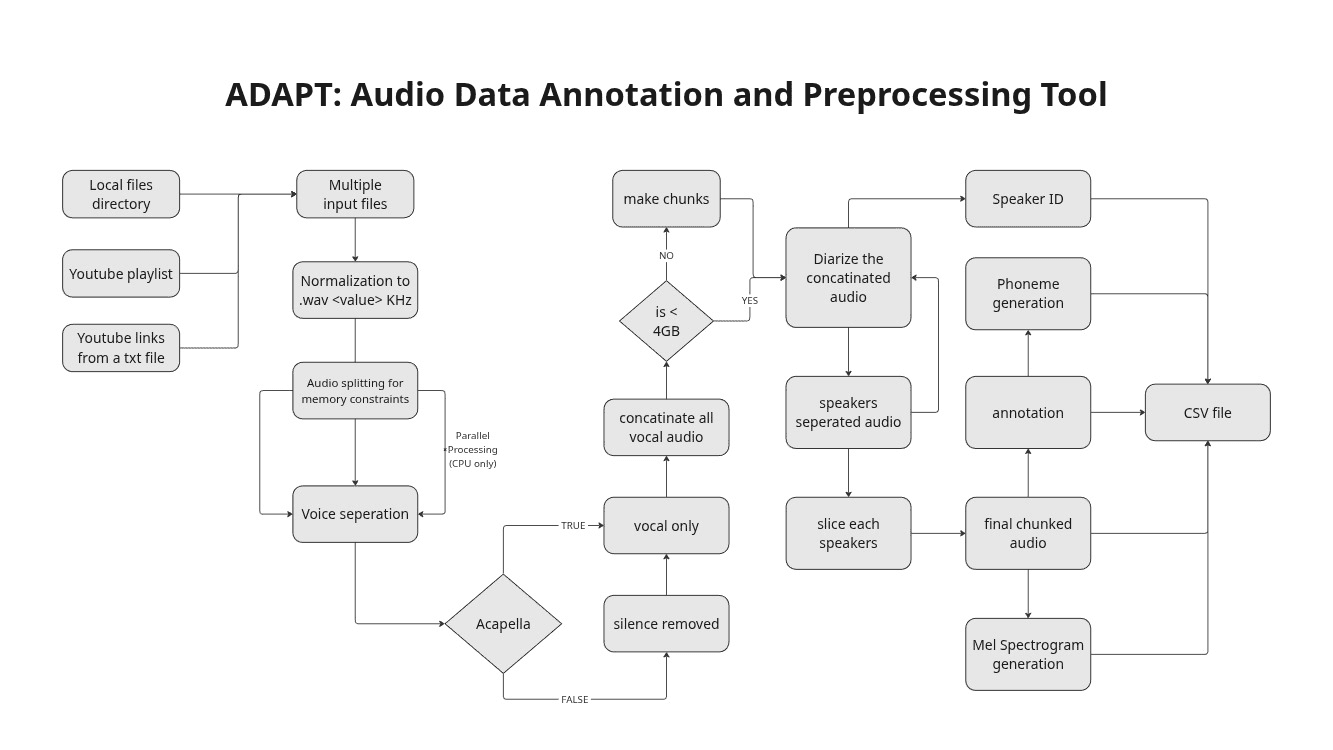
Pipeline architecture demonstrating sequential, non-destructive processing from raw ingestion to final chunked phonetic metadata.
Problem Statement
Building high-quality datasets for Text-to-Speech (TTS) and Automatic Speech Recognition (ASR) models is historically bottlenecked by manual labor. Extracting clean speech from noisy YouTube streams, accurately diarizing multiple speakers, stripping silence, and generating aligned phonetic metadata requires hundreds of hours of manual annotation. Furthermore, automated pipelines often crash due to GPU VRAM limits on long files or lose track of speaker identities when audio is chunked.
Architecture Breakdown
- Ingestion & Normalization: Leverages
yt-dlpandffmpegto pull raw audio from URLs or local directories, standardizing to a unified mono sample rate (e.g., 44.1kHz). - Vocal Isolation & Memory Management: Utilizes
Demucsfor state-of-the-art music and noise separation. To prevent Out-Of-Memory (OOM) faults on consumer GPUs, a pre-chunking layer splits massive files into configurable durations prior to tensor processing. - Global Speaker Diarization: Employs
pyannote.audiofor temporal speaker segmentation and embedding extraction. - Slicing & Transcription: Filters dead air via WebRTC Voice Activity Detection (VAD) and feeds valid speech utterances into batched
Whispermodel inference.
Why This Needed Custom Engineering
When scaling dataset generation to multi-hour audio files, strict hardware VRAM limits mandate chunking the audio before neural network processing. However, naive chunking breaks continuous speaker diarization: "Speaker 1" in Chunk A might be incorrectly labeled as "Speaker 3" in Chunk B, ruining the integrity of single-speaker TTS datasets.
ADAPT solves this structural flaw natively. Instead of blindly merging chunk outputs, ADAPT extracts neural speaker embeddings for every detected segment. It then performs a global Agglomerative Clustering pass using cosine similarity on these embeddings to unify speaker IDs across the entire dataset before the final slicing phase.
Operational Core Challenges and Fixes
| Challenge | Technical Description | Pipeline Mitigation Strategy |
|---|---|---|
| GPU VRAM Exhaustion | Heavy models like Demucs crash when loading entire multi-hour WAV tensors into memory. | Implemented a parameter-driven pre_chunking module to slice raw audio into digestible 10-minute fragments prior to vocal separation. |
| Cross-Chunk Speaker Identity Loss | Sequential diarization of chunked files creates overlapping or disjointed localized speaker labels. | Engineered a global clustering layer (AgglomerativeClustering) that maps temporary local IDs to a master embedded spatial grouping. |
| Low-Resource Language Phonetics | Universal IPA generators (espeak-ng) often fail on structurally complex Indic scripts like Malayalam. | Integrated a custom grapheme-to-phoneme backend using a modified mlphon_v2 dictionary for precise Malayalam phonetic transcriptions. |
| Non-Speech Artifacts | Breaths, clicks, and room tone inflate dataset size and confuse acoustic models during training. | Calibrated a WebRTC VAD thresholding filter during the slicing phase to aggressively drop non-vocal audio frames. |
Pipeline Output & Artifact Generation
ADAPT operates entirely non-destructively, caching outputs at each phase to allow for pipeline resumption and modular debugging. The final export provides everything an ML engineer needs for immediate model training.
| Artifact | Output Format | Purpose |
|---|---|---|
| Utterance Audio | .wav (Mono, 44.1kHz) | Clean, isolated vocal slices normalized for acoustic modeling. |
| Mel Spectrograms | .png | Visual frequency representations generated via librosa for model evaluation. |
| Master Index | metadata.csv | Links exact file paths to speaker IDs, timestamps, raw transcriptions, and phonetic tokens. |
Engineering Outcome
ADAPT effectively reduces the data curation timeline from weeks to hours. By successfully managing memory limits without sacrificing the contextual integrity of speaker diarization, it provides a highly reliable, scalable infrastructure for building proprietary voice cloning, TTS, and ASR datasets on consumer-grade hardware.