Synthetic Dataset Generation ·
M-Synth: High-Fidelity Synthetic OCR Dataset Generator for Indic Scripts
A production-grade, memory-safe synthetic data generator designed to solve the chronic data scarcity problem for Indic OCR pipelines. It produces optimally balanced, physically realistic training images by combining linguistic corpus analysis with advanced image synthesis.
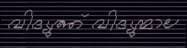
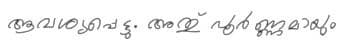




Synthesized Malayalam text with severe skew, paper texture background, and physical scan artifacts.
Problem Statement
Developing robust Optical Character Recognition (OCR) systems for Brahmic scripts specifically Malayalam is historically bottlenecked by chronic training data scarcity. Malayalam orthography represents an exceptionally high linguistic complexity, featuring over 900 valid character combinations, intricate overlapping ligatures (കൂട്ടക്ഷരം) and historical Lipi shifts (clashes between legacy and reformed scripts).
Existing text corpora are heavily skewed toward common characters, causing CTC-based deep recognition models to suffer from alignment collapse and failure on rare glyphs (e.g. ൄ, ൺ, ഝ, ഢ). Furthermore, collecting and manually annotating diverse, physically realistic scanning anomalies and document degradation conditions is resource-prohibitive.
Architecture Breakdown
M-Synth resolves this data constraint via a two-phase, memory-safe pipeline that synthesizes highly balanced, physically realistic document image strips:
- Linguistic Corpus Balancing (Phase 1): Utilizes stratified reservoir sampling (Algorithm R) to stream massive raw text corpora into memory-restricted environments, building a distribution-controlled manifest. This phase handles chillu canonicalization (resolving legacy ZWJ sequences) and dynamically injects rare character templates.
- High-Fidelity Rendering & Synthesis (Phase 2): Uses the vector-based Pango/Cairo rendering engine to shape complex Brahmic ligatures flawlessly, backed by
fontToolscoverage analysis. Renders are then fed through an advanced photometric and geometric augmentation pipeline.
Why This Needed Custom Engineering
Brahmic text rendering is inherently non-linear; simple character-by-character glyph plotting causes severe spatial overlap and font-breakage. M-Synth uses Cairo/Pango text-shaping paradigms to ensure correct ligature composition, but this introduces processing challenges when scaling to millions of samples.
Moreover, naive random text generation leads to highly unnatural letter distributions. M-Synth addresses this by implementing Stratified Reservoir Sampling with custom script classifiers to dynamically balance five distinct script categories (Malayalam-only, English-only, mixed-script, symbol-heavy, and rare character focus) and length buckets (short, medium, long) in a single streaming pass.
Synthesized Script Showcase & Visual Capabilities
Below is a live display of representative synthetic images generated by M-Synth, showcasing each script category and its associated visual properties:
| Synthetic Preview Image | Script Category | Structural Ligature Trait | Applied Augmentations & Visual Properties |
|---|---|---|---|
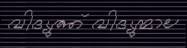 | Malayalam | Features legacy chillu markers (ൺ, ൻ) and complex overlapping glyph structures | Skewed layout, paper-texture background overlay, contrast degradation |
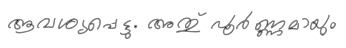 | Malayalam | High-density conjuncts with correct shaping | Motion-blur simulation, localized shadow casting, slight horizontal shear |
 | English | Latin numeral sequences and alphabetic strings | Lined notebook paper background, ink bleed-through effect, slight angle shift |
 | English | Latin character series | Grid paper texture, elastic character distortion, salt-and-pepper noise, dilation |
 | Mixed-Script | Code-mixed English + Malayalam token sequence | Wrinkled paper texture, light perspective distortion, localized contrast compression |
 | Mixed-Script | Code-mixed Indic-Latin character sequence | Heavy ink bleed simulation, spatial erosion, Gaussian blurring, noise overlays |
Key Technical Challenges & Mitigations
| Challenge | Engineering Description | Pipeline Mitigation Strategy |
|---|---|---|
| Brahmic Font Spacing Breaks | Standard PIL/Pillow libraries render Brahmic characters sequentially, separating complex joint ligatures into disjointed glyph components. | Engineered a vector-level rendering layer utilizing Pango/Cairo to perform proper HarfBuzz-backed text shaping before canvas creation. |
| System Memory Exhaustion | Processing multi-gigabyte raw text corpora to find rare character sequences crashes host systems due to RAM limits. | Built a stream loader that processes JSONL/TXT inputs incrementally via Python generators and samples a fixed-size dataset using Algorithm R. |
| Character Truncation in Crops | Applying heavy geometric distortions (skew, rotation, perspective) often cuts off start/end characters on tight text boundaries. | Integrated dynamic canvas boundary calculation in get_text_dimensions to add elastic padding to the canvas prior to rotation and crop. |
| Silent Font Deficit Corruption | Many Unicode fonts lack full glyph maps for rare Malayalam glyphs, rendering empty blocks (tofu) in synthetic datasets. | Implemented fontTools font analysis to pre-scan system fonts and dynamically rank font fallbacks based on precise sub-range Unicode coverage. |
Engineering Outcome
The M-Synth pipeline enables rapid, deterministic creation of robust training datasets for OCR architectures like PaddleOCR and TrOCR. By ensuring uniform character-level coverage and simulating complex real-world scanning defects, models trained on M-Synth corpora exhibit SOTA generalization capabilities, effectively mitigating the Indic low-resource script data barrier.